Crawl-Budget steuern, optimieren und bessere ranken
Eines der wichtigsten Themen für Websites, wenn es um Suchmaschinenoptimierung geht, ist nach wie vor Crawling und Indexierung. Vor allem: Dem Googlebot durch gezielte Steuerung des Crawlings alle Unterseiten und Produkte Ihrer Website zugänglich machen, sodass diese heruntergeladen und in die Suchergebnisse aufgenommen werden können.

Crawl-Budget ist essentiell und begrenzt
Damit Ihr Webshop für User über Google optimal erreichbar ist, wollen Sie vermutlich so viele Seiten wie möglich im Google Index haben. Doch damit Google auch alle Seiten in den Index aufnehmen kann, müssen diese zuerst vom Googlebot gecrawlt werden. Das bedeutet, der Googlebot besucht oder “scannt” jede einzelne Unterseite, lädt sie als HTML herunter und entscheidet, ob sie indexiert und in der Suchmaschinen positioniert werden soll.
Gerade bei Onlineshops kann das Crawling schnell zum Problem werden, wenn Sie einen größeren Shop mit vielen Produkten und Kategorien haben. Denn: Der Googlebot crawlt nur eine begrenzte Anzahl an Seiten Ihrer Domain. Die Menge an Unterseiten, die gecrawlt werden und deren Crawl-Frequenz, bezeichnet man als Crawl-Budget. Jetzt fragen Sie sich natürlich:
Wie viel Crawl-Budget hat mein Onlineshop?
Das ist von mehreren Faktoren abhängig: Zum einen von der generellen Größe und organischen Sichtbarkeit Ihres Onlineshops und zum anderen auch von der allgemeinen technischen Gesundheit. Die Menge an 404-Fehlern und Serververbindungsproblemen, die Tiefe der Website-Struktur, interne Verlinkungen, etc. sind hierbei wichtige Aspekte. Ebenfalls relevant für das heruntergeladene Datenvolumen ist der Pagespeed Ihres Shops – insbesondere die Serverantwortzeit und Time to First Byte (TTFB). Denn: Je länger Ihre Seite braucht, um zu antworten, desto weniger wird der Googlebot auf Dauer herunterladen.
Wie Ihr Crawl-Budget konkret aussieht und wann wie viele Seiten gecrawlt werden, können Sie in der Google Search Console unter Crawling-Statistiken überprüfen. Den Bericht finden Sie unter den „Vorherigen Tools und Berichten“, da er aktuell nur in der alten Version der Search Console vorliegt:
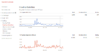
Hierbei wird generell zwischen gecrawlten Seiten und heruntergeladenem Datenvolumen unterschieden. Wie hier im Beispiel angeführt, kann das Crawl-Volumen in beiden Dimensionen starken zeitlichen Schwankungen unterliegen. Der Peak zwischen September und Oktober im Beispiel war eine Folge großer technischer Veränderungen auf der Domain. Hier kann man sehr genau sehen, dass der Googlebot starke Veränderungen registriert hat und infolgedessen das Crawl-Volumen deutlich erhöht hat. Ihr Crawlvolumen muss also keinesfalls immer gleich bleiben. Da Crawl-Ressourcen Google faktisch Geld kosten, wird Ihr Budget so minimal wie möglich gehalten. Für die richtige Nutzung des zur Verfügung gestellten Volumens sind folglich Sie verantwortlich.
Budget optimieren – Diese Fehler verschwenden wertvolles Crawl-Budget
Wie maximieren Sie also den Ertrag, den Sie durch das von Google zur Verfügung gestellte Budget generieren können? In erster Linie, indem Sie optimale technische Bedingungen schaffen. Das bedeutet, Sie sollten vermeiden, dass der Googlebot jede Menge Unterseiten crawlt, die nicht relevant sind oder gar nicht in den Index gehören. Besonders in Onlineshops und Event-Seiten entstehen hierdurch eine extrem hohe Anzahl an URLs, was schnell zu Problemen bei der Indexierung führen kann. Im Folgenden erfahren Sie die häufigsten Gründe dafür:
Parameter in den URLs
Unkontrollierte Parameter in den URLs Ihres Shops können schnell dazu führen, dass der Bot die Orientierung verliert. Wenn Parameter nötig sind, behalten Sie den Überblick über deren Variationen und konfigurieren Sie diese in der Google Search Console. Eine weitere Möglichkeit ist, das Crawling der Parameter über die robots.txt auszuschließen. Diese Variante ist allerdings etwas fehleranfälliger und – sind wir ehrlich – damit macht man es sich ein bisschen zu einfach!
Durch Filtermöglichkeiten erzeugte URLs
Wenn Ihr Shop Filtermöglichkeiten nutzt, die eigene URLs erzeugen, kann das zu einer unkontrollierbaren Menge an URLs führen. Allerdings können eigene URLs durch Filtermöglichkeiten als SEO-Strategie genutzt werden. Wenn Sie diese Technik verwenden, empfehlen wir Ihnen, nur aus wenigen ausgewählten, speziell keyword-optimierten Filtermöglichkeiten URLs generieren zu lassen. So halten Sie die Menge an zusätzlichen URLs gering und schonen Ihr Crawl-Budget.
Dynamisch generierte URLs
Wenn auf Ihrer Domain Dokumente dynamisch erstellt werden, sollten Sie unbedingt das Ausmaß im Auge behalten. Das gilt ebenso für User-generierten Content, wenn Sie Probleme mit Ihrem Crawl-Budget haben.
Duplicate Content
Das Kryptonit guter organischer Rankings! Duplikate sind nicht nur schlecht für die Rankings Ihres Webshops, sondern verbrauchen auch noch jede Menge Crawl-Budget. Sie über das Meta Noindex zu deindexieren ist auch nur eine vorübergehende Lösung, denn: Dadurch werden Duplikate zwar nicht mehr indexiert, aber weiterhin gecrawlt. Und auch ein Ausschluss über die robots.txt ist kein Garant dafür, dass der Googlebot nicht doch mal vorbeischaut. Deshalb sollten Sie Duplicate Content im Grunde immer vermeiden.
Den Indexierungsstatus der wichtigsten Produkte einfach in Google checken
Sie können ganz einfach prüfen, ob Ihre Produkte oder Unterseiten bereits im Google Index angekommen sind oder nicht. Nehmen Sie einfach die URL der Seite, die Sie überprüfen wollen, setzen Sie „site:“ davor, und suchen Sie danach. Ein Beispiel:
Ist die Seite indexiert, sollte sie in den Suchergebnissen auftauchen. Tut sie das nicht, wurde sie eventuell nicht gecrawlt und indexiert.
Crawl Budget steuern – Den Googlebot durch die Website leiten – 8 Tipps
Um Ihr verfügbares Crawl-Budget optimal nutzen zu können, sollten Sie alle vorhandenen Möglichkeiten nutzen, um dem Googlebot den Weg durch das Unterholz Ihres Produktdschungels zu ebnen. Und das können Sie mithilfe dieser vier Punkte:
1. Interne Verlinkung
Der Googlebot kann nur Seiten crawlen, die er auch über Verlinkungen erreicht. Dafür nutzt der Bot in erster Linie zwei Quellen: Externe Links von anderen Domains und interne Links innerhalb der eigenen Domain. Da Sie insbesondere über letztere Autorität haben, sollten Sie eine starke interne Verlinkung der Produkte gewährleisten, die Sie gerne im Index wiederfinden möchten. Je tiefer in der URL-Struktur ein Produkt liegt, umso wichtiger ist es, dass der Crawler es über Linkketten von der Startseite aus erreichen kann. Hier spielt natürlich eine gut konzipierte Webseitenstruktur eine große Rolle. Achten Sie auch bei neuen Produkten stets auf eine konsistente interne Verlinkung. Gleichzeitig sollten Sie aber die Zahl der Links nicht ins Unübersichtliche wachsen lassen. Bleiben Sie bei „maximal einigen Tausend“ (Google Richtlinien für Webmaster).
2. Konzentriertes Angebot
Je mehr Seiten Sie von der Indexierung ausschließen, umso mehr Ressourcen hat der Googlebot, die wichtigen Produkte und Kategorien regelmäßig zu crawlen. Also gilt es sich Gedanken zu machen, welche Seiten Sie im Index brauchen und welche eher Ihr Crawl-Budget verschwenden. Das betrifft allerdings nicht nur Duplikate, sondern auch bestimmte Seitentypen oder für die organische Suche irrelevante Kategorien. So sind z.B. Suchergebnisseiten (interner Site-Search) laut den Google Richtlinien von der Indexierung auszuschließen, da sie Seiten mit geringem Nutzerwert darstellen.
Dafür ist es oft nötig, Seiten von der Indexierung auszuschließen. Generell haben Sie die Möglichkeit, Produkte durch Meta-Noindex aus dem Index auszuschließen oder durch die robots.txt das Crawlen zu verhindern. Aber achten Sie darauf, dass Sie nicht beide Lösungen gleichzeitig anwenden: Sie negieren einander.
3. Sitemap
Eine Sitemap ist eine XML-Datei, die ein „Inhaltsverzeichnis“ aller URLs auf Ihrer Domain ist. Diese Datei erleichtert so dem Crawlbot das Verständnis und Erfassen der Struktur Ihrer Webseite. Weitere Informationen über eine sauber strukturierte Website finden Sie in SEO für Onlineshops – Teil 2.
4. Die robots.txt
Die robots.txt ist ein einfaches Textdokument, an dem sich Crawler orientieren können. Hier können Sie Regeln zum Crawling Ihrer Domain bestimmen und ggf. Seiten oder Verzeichnisse ausschließen.
5. NoFollow Verlinkungen nutzen
Wenn Sie von Ihrer Seite auf andere Seiten verlinken, sollten Sie dies am besten mit einem NoFollow Attribut tun. Andernfalls folgt der Google-Bot der Verlinkung und verlässt Ihre Seite früher, als Ihnen lieb ist.
6. Page Speed
Die Geschwindigkeit Ihrer Website spielt eine wichtige Rolle für das Crawl-Budget des Google-Bots. Wenn Ihre Seite lange Ladezeiten hat, wird der Google-Bot weniger Zeit damit verbringen, alle Ihre Seiten zu crawlen und weniger Seiten bei einem Crawl indexieren. Aus diesem Grund sollten Sie die Ladezeiten Ihrer Website regelmäßig im Blick behalten und ggf. optimieren.
7. Broken Links
Defekte interne Verlinkungen führen den Google-Bot in eine Sackgasse und verbraucht unnötig viel Crawl-Budget. Kommt dies häufiger vor, verlässt der Bot Ihre Seite wieder und hat dabei womöglich viele Seiten nicht gecrawlt, die nun nicht indexiert werden können.
8. Aktuelle Inhalte
Pflegen Sie die Inhalte Ihrer Website oder Ihres Onlineshops und halten Sie diese aktuell. So sieht der Google-Bot bei jedem Crawling, dass es Neuerungen gibt, ordnet Ihrer Website ein größeres Crawl-Budget zu und crawlt Ihre Seite häufiger.
Fazit
Der Google-Bot hat für das Crawling Ihrer Website ein vorbestimmtes Crawl-Budget. Dieses lässt sich mit den richtigen SEO-Maßnahmen steuern und optimieren, damit die einzelnen Seiten und Produkte Ihrer Website oder Ihres Onlineshops auch möglichst schnell indexiert werden und auf den vorderen Rankings der Suchmaschine landen. Tools, wie die Google Search Console oder Screaming Frog helfen Ihnen dabei mögliche Fehlerpotentiale Ihrer Website zu erkennen und zu beseitigen.
Brauchen Sie Unterstützung bei diesem Thema?
Sprechen Sie uns unverbindlich an und lassen Sie sich von uns beraten.
So bauen Sie die perfekte Website-Struktur
Eine saubere Website-Struktur ist ein absolutes Muss für den User, ein wichtiger Aspekt für den Crawler und gleichzeitig eine Herausforderung für den komplexen Onlineshop. Besonders bei Shops mit breitem Warensortiment sollte bereits früh geplant werden, wie die Ebenenstruktur der Website…
Klickstarke Meta Tags in 4 Schritten
Sie wollen, dass Ihre Website potenzielle Käufer über die Suchmaschine anlockt? Dann sollten Sie sich darüber Gedanken machen, wie Ihre Website in den Suchergebnissen dasteht. Und zwar nicht nur für welche Suchbegriffe, sondern auch wie die Suchergebnisse aussehen: Regen Sie…
Duplicate Content Check: Wie Sie doppelte Inhalte finden und vermeiden
Wie entsteht Duplicate Content und was können Sie tun, um ihn zu bekämpfen? Oder besser: Um ihn von vorneherein zu vermeiden? Duplicate Content (deutsch: doppelter Inhalt) bezeichnet Inhalte, die in gleicher oder sehr ähnlicher Form unter verschiedenen URLs im Web…


