Duplicate Content Check: Wie Sie doppelte Inhalte finden und vermeiden
Wie entsteht Duplicate Content und was können Sie tun, um ihn zu bekämpfen? Oder besser: Um ihn von vorneherein zu vermeiden? Duplicate Content (deutsch: doppelter Inhalt) bezeichnet Inhalte, die in gleicher oder sehr ähnlicher Form unter verschiedenen URLs im Web zu finden sind. Besonders für große Seiten wird das schnell zum Problem. Lesen Sie hier, was Sie gegen Duplicate Content tun können.

Was ist Duplicate Content?
Unter Duplicate Content versteht man das Vorhandensein von identischem oder sehr ähnlichem Inhalt auf verschiedenen Webseiten. Dies gilt sowohl für gleiche als auch unterschiedliche Domains. Im Folgenden betrachten wir dafür einige Beispiele für die verschiedenen Arten von Duplicate Content am Beispiel eines Onlineshops.
Externer Duplicate Content
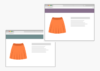
Externer Duplicate Content sind gleiche Inhalte, die sich auf verschiedenen Seiten im Web befinden. Ein klassisches Beispiel für den Onlineshop: Produktbeschreibungen.
Stellen Sie sich vor, Sie führen in Ihrem Onlineshop für Damenröcke den Faltenrock Mango Summer Breeze einer bekannten Modemarke. Sie beziehen den Artikel vom Hersteller und verkaufen ihn mit freundlicher Genehmigung von ebendiesem. Die Produktbeschreibung haben Sie ebenfalls vom Hersteller, da dieser das Produkt auch in seinem eigenen Shop vertreibt – ganz zu schweigen von den 17 anderen Onlineshops, die alle ebenfalls den Mango Summer Breeze anbieten. Wen wird Google wohl als Originalquelle der Produktbeschreibung identifizieren? Raten Sie mal…
Das Fazit: Die Produkte und – schlussendlich kritisch – die Produktbeschreibungstexte existieren nicht nur in Ihrem Shop, sondern auch auf anderen Domains.
Die Konsequenz: Sie werden unmöglich ein Spitzenranking für den Mango Summer Breeze aufbauen können! Google wird Ihren Content als minderwertig einstufen. Sollten sich die Duplikate in Ihrem Shop bis zu dem Punkt stapeln, dass man Ihnen Absichtlichkeit und Contentklau vorwerfen könnte, riskieren Sie sogar eine Abstrafung durch Google.
Im schlechtesten Fall wirkt sich das nicht nur negativ auf die google Position des Artikels aus, sondern auch auf andere Positionen ihrer Website, da Sie google ein unseriöses Signal senden.
Interner Duplicate Content
Interner Duplicate Content ist jede Art von Duplikat, die sich auf Ihrer eigenen Domain befindet und dort unter verschiedenen URLs abrufbar ist. Natürlich können sich doppelte Inhalte intern und extern auch überschneiden, wenn Sie beispielsweise eine Produktbeschreibung von einer anderen Domain verwenden, die in Ihrem Shop dann auch noch mehrfach auftaucht.
Wie kommt es zu doppelten Inhalten?
Produkte in mehreren Kategorien
Aus Gründen der Usability ist es meist von Vorteil für den User, wenn Produkte in mehreren Kategorien auftauchen. So könnte der Mango Summer Breeze unter www.heart-rock-shop.de/roecke/faltenroecke, www.heart-rock-shop.de/roecke/sommerroecke oder auch www.heart-rock-shop.de/sonderangebote zu finden sein.
Tauchen Produkte Ihres Shops in mehreren Shop-Kategorien auf, ist das weniger ein inhärentes Problem von Duplicate Content als vielmehr eine Herausforderung der Websitestruktur Ihres Webshops. Wirklich problematisch wird es hierbei jedoch erst, wenn die Produktbeschreibungen umfangreicher gestaltet sind.
Oft tauchen auch Seitenduplikate unter ähnlichen aber unterschiedlichen URLs – mit und ohne Trailing Slash – auf. Achten Sie hier unbedingt auf Konsistenz bei der URL-Erstellung.
Duplicate Content durch Paginierung
Lange Produktlisten sind in vielen Shopsystemen über mehrere Seiten verteilt, um den User nicht auf den ersten Blick mit Produkten zu erschlagen. Im Hinblick auf Duplicate Content kann es problematisch werden, wenn sich SEO-Elemente und Textbausteine auf den Seiten wiederholen. Hier verwendet man am besten Canonical-Tags und fügt Paginierung für die verschiedenen Seiten hinzu.
Duplicate Content durch Größen & Farben
Eines der größten Probleme für internen Duplicate Content im Onlineshop stellen Produktvariationen wie verschiedene Größen- und Farbauswahlen für Produkte dar.
Kommen wir zurück zu unserem Faltenrock: Sie vertreiben den Mango Summer Breeze, den es noch in einer weiteren Farbvariation gibt – Sea Green Tidal Wave.
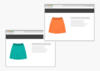
Die Produkte sind in Ihrem Onlineshop unter verschiedenen URLs zu finden und generieren so Duplicate Content, denn bis auf den Namen des Produkts sind die Beschreibungstexte identisch. Mehr noch: die beiden Produktvariationen konkurrieren in den SERPs für diverse wichtige Keywords miteinander!
Die beste Lösung hierfür ist, nur eine Produktseite zu erstellen, auf der die Farbe des Produkts per Filter ausgewählt werden kann, sodass sich die URL nicht ändert.
Eine weitere Lösung wäre ein Canonical-Tag von der weniger wichtigen Produktvariationen auf das gewünschte Hauptprodukt zu setzen. Das würde allerdings dazu führen, dass nur das Hauptprodukt in den Google Suchergebnissen erscheint!
Brauchen Sie Unterstützung?
Unsere SEO Spezialisten helfen Ihnen gerne dabei, Duplicate Content und andere negative Signale für google aus der Welt zu schaffen und damit bessere Rankings in der Suchmaschine zu erreichen. Melden Sie sich gerne ganz unkompliziert für ein kostenloses Beratungsgespräch und wir finden heraus, wie wir Sie am besten unterstützen und noch erfolgreicher machen können.
Beeinflusst Duplicate Content das Ranking?
Kurz gesagt: Ja.
Google und der Googlebot bevorzugen einzigartigen „unique“ Content. Das Ziel ist es zu einer Suchanfrage den relevantesten Inhalt auszuliefern. Ist nun Duplicate Content vorhanden, dann weiß Google nicht welcher Inhalt relevanter ist und teilt diesen Relevantswert unter den beiden Seiten auf. Die Folge ist eine Abstrafung im Ranking. Es kann sogar passieren, dass die Seite nicht indexiert wird. Besonders externer Duplicate Content ist ein Problem, da Google hier den Urheber des Originals nicht feststellen kann.
Es gibt natürlich Situationen, in denen sich doppelte Inhalte nicht vermeiden lassen. Stellt man beispielsweise eine Druckversion einer Webseite zur Verfügung so ist diese eine inhaltliche Kopie. Hier kann man mit einem Canonical-Tag deutlich machen, dass es sich bei der Druckversion um eine Kopie handelt und verweist auf das Original.
Weitere Quellen von Duplicate Content
Es gibt natürlich noch viel mehr Ursachen für Duplicate Content. Nachfolgend werden häufige Ursachen und eine Lösung beschrieben.
Duplicate Content durch falsche Serverkonfiguration bei Subdomain
Diese Art des doppelten Inhalts ist wohl eine der Häufigsten. Der Server antwortet auf allen Subdomains mit dem selben Content. Beispielsweise führt der Aufruf der Domain „www.beispiel.de“ zum gleichen Inhalt wie der Aufruf der Domain „beispiel.de“. Richtig kritisch wird es, wenn der Server bei allen Subdomains mit dem gleichen Inhalt antwortet. Die Lösung ist jedoch immer die selbe: Der Server muss korrekt konfiguriert werden. Bei einem Apache Server nutzt man das mod-rewrite Modul und konfiguriert eine .htaccess Datei im Root-Verzeichnis seines Webauftritts. Somit legt man sich auf eine Domain fest und die übrigen bekommen eine 301-Weiterleitung. Der Inhalt der .htaccess kann zum Beispiel so aussehen:
# ! Weiterleitung Subdomains auf https und www !
RewriteCond %{HTTP_HOST} !^www.beispiel.de$ [NC]
RewriteRule (.*) https://www.beispiel.de/$1 [R=301,L]
Duplicate Content durch den Footer
Der Footer eines Webauftritts wird auf jeder Seite angezeigt. Prädestiniert für doppelten bzw. mehrfachen Inhalt, da sich oft viel zu viele Informationen im Footer befinden. Hier ist die Lösung: Weniger ist mehr. Ein stichpunktartiger Footer ist vollkommen ausreichend und erfüllt seinen Zweck. Komplexere Inhalte gehören auf eine eigene Unterseite.
Duplicate Content durch länderspezifische Domains
Ein und dieselbe Domain mit mehreren Übersetzungen in Verzeichnissen (www.beispiel.de/en/ und /it/) gilt nicht als Duplicate Content. Für große Unternehmen kann es sinnvoll sein seinen Content in mehreren Sprachen anzubieten. Teilweise ist dies sogar nötig, da unterschiedliche Länder auch unterschiedliche Steuersätze haben. Aber wie geht man mit Domains um, die ihren Content in mehreren Ländern mit der selben Sprache anbieten?
Als Beispiel nehmen wir die DACH-Länder. Ein Shopbetreiber ist mit seiner Domain in diesen drei Ländern aktiv und hat eigene Verzeichnisse für die jeweiligen Länder und zwar: „www.beispiel.com/de/“, „www.beispiel.com/at/“ und „www.beispiel.com/ch/“. Hier handelt es sich um Duplicate Content, da sich der selbe Content in drei Verzeichnissen befindet. Doch Google hat auch hierfür eine Lösung.
Mit dem hreflang-Tag werden Webseiten-Inhalte einer Sprache oder Region zugeordnet. In unserem Beispiel sollte der hreflang-Tag auf der deutschen Seite so aussehen:
www.beispiel.com/de/
Übrigens: Wir unterstützen Sie gerne dabei Duplicate Content zu vermeiden und Ihre Google Positionierung zu verbessern. Buchen Sie jetzt ganz einfach ein unverbindliches Beratungsgespräch bei uns.
Jetzt Kontakt per E-Mail oder Telefon aufnehmen
<link rel=“alternate” hreflang=“de-AT” href=“https://www.beispiel.com/at/”/>
<link rel=“alternate” hreflang=“de-CH” href=“https://www.beispiel.com/ch/”/>
Wie kann ich meine Webseite auf Duplicate Content überprüfen?
Es gibt viele Tools, um Ihnen die Suche nach Duplicate Content zu erleichtern. Praktisch ist: sowohl interne als auch externe Überschneidungen lassen sich mit diesen Anwendungen überprüfen.
- copyscape.com (URL einsetzen)
- webconfs.com (zwei URL’s vergleichen)
- Google Search Console (Indexabdeckung > Ausgeschlossen)
- Ryte (Inhalt > Duplicate Content)
- Ahrefs (Anleitung)
Allerdings ist auch der Google Index ein akkurater Indikator für schädliche doppelte Inhalte. Mithilfe von Suchoperatoren finden Sie schnell mehrfach indexierte Produktbeschreibungen oder gleiche Produkttitel unter verschiedenen URLs.
Externen Duplicate Content im Google Index finden
Externen Duplicate Content aufzuspüren ist eine leichte Übung! Kopieren Sie einfach einen Teil des verdächtigen Contents (bis zu 30 Zeichen) aus Ihrem Shop und suchen Sie danach in Anführungszeichen:
In den Suchergebnissen zeigt Google Ihnen nun alle Seiten, die exakt diesen Textbaustein enthalten. Die Reihenfolge der Suchergebnisse ist außerdem ein guter Indikator der Relevanz der Suchergebnisse für Google.
Internen Duplicate Content aufspüren
Schwerer wird es schon, wenn nicht ganz klar ist, wo sich der doppelte Content verbirgt. Um internen Duplicate Content zu finden, können Sie ebenfalls den Google Index nutzen – bloß müssen Sie dabei die Suche auf Ihre Domain beschränken. Das können Sie ebenfalls mithilfe von Googles Suchoperatoren. Nehmen wir an, Ihre Domain lautet www.heart-rock-shop.de. Mit:
finden Sie alle indexierten Seiten Ihrer Domain, die den String Faltenrock Mango Summer Breeze beinhalten. Wenn das noch nicht genau genug ist, können Sie weitere Operatoren verwenden, um die Suche einzugrenzen:
gibt Ihnen alle Seiten Ihrer Domain, die Mango Summer Breeze im Meta-Title enthalten. Wenn Sie zusätzlich noch Produkte mit einem bestimmten Produktparameter (oder anderen String) in der URL suchen, verwenden Sie inurl:
Sie können ebenfalls bestimmte Seiten oder Verzeichnisse von den Suchergebnissen ausschließen, indem Sie ein Minus vor den site-Operator setzen:
Das Beispiel findet Produkte in verschiedenen Kategorien mit dem Title Mango Summer Breeze auf Ihrer Domain, schließt aber gleichzeitig Suchergebnisseiten aus, für den Fall, dass Sie sich um diese schon gekümmert haben.
Wenn Sie etwas tiefer in die Materie einsteigen wollen, finden Sie bei uns eine Anleitung, wie Sie Domain internen Duplicate Content mit dem Screaming Frog finden können.
Top 4 SEO Maßnahmen gegen Duplicate Content
Nun, da Sie alles über Duplicate Content wissen, werden Sie ihm in Zukunft natürlich aus dem Weg gehen. Sie wissen, wie Duplikate entstehen und können sie in Zukunft präventiv umgehen. Wie aber mit den doppelten Inhalten umgehen, die sich bereits vor der Erleuchtung angesammelt haben? Hier sind die Top 4 Tipps zur Beseitigung von Duplicate Content:
1. Canonicals setzen
Ein Canonical-Tag im Head-Bereich einer Website kennzeichnet deren inhaltliches Verhältnis zu einer Originalquelle. Dies ist eine besonders gute Lösung für internen Duplicate Content, wenn Produkte in mehreren Kategorien im Shop auftauchen. Findet man wie in unserem Beispiel also den Rock unter mehreren Kategorien, kann man auf allen Seiten, die nicht das Original sind, folgendes Tag in den HTML-Head der Seite einfügen:
Die Suchmaschine weiß somit, dass nur das Produkt unter faltenrock/mango-summer-breeze indexiert werden soll.
2. Deindexierung durch Meta-Noindex
Wenn die Seite Duplicate Content enthält, aber Ihrer Einschätzung nach kein relevantes Suchergebnis für Ihre Besucher darstellt, können Sie die Seite auch deindexieren – sprich sie aus dem Google Suchergebnis Index nehmen. Dafür bauen Sie in den Head-Bereich der Seite das Tag:
ein. Dieses wird dem Googlebot empfehlen, die Seite nicht zu indexieren.
3. Verzeichnisse durch die robots.txt vom Crawling ausschließen
Wollen Sie hingegen verhindern, dass ganze Verzeichnisse wie z.B. /search-results/ gecrawlt werden, können Sie den Googlebot über die robots.txt vom Crawlen des entsprechenden Verzeichnisses abhalten:
Disallow: /search-results/
4. Unique Content schaffen
Dies ist nicht nur die absolut beste Lösung, um generell Duplicate Content zu vermeiden, sondern auch oft die einzig effektive, um externen DC wie z.B. in Produktbeschreibungen unter Kontrolle zu bekommen – denn die Lösungen 1 & 2 greifen nur bei der eigenen Domain. Das Setzen eines Canonicals auf die Originalquelle würde nur zur Folge haben, dass die eigene Produktseite vermutlich gar nicht indexiert wird.
Also: Das Zauberwort zur Öffnung der Tür in die SERPs lautet wie so oft: Unique Content! Natürlich ist das redaktionell sehr aufwendig und kann besonders bei großen Webauftritten nicht zeitnah umgesetzt werden, aber Google wird Ihre Bemühungen belohnen.
Beispiel gefällig?
Wir haben die Struktur übersichtlicher gemacht und dafür gesorgt, dass Duplicate Content vermieden wird. Zur Case Study von kölnticket.de »
Häufige Fragen schnell beantwortet
1. Ist Duplicate Content schädlich für SEO?
Ganz klar ja. Doppelte Inhalte senden google das Signal, dass auf Ihrer Website etwas nicht stimmt. Entweder können die google Bots nicht bestimmen, welche Website das Original ist und platzieren Ihren Inhalt auf den hinteren Positionen der Suchmaschine oder google straft ihre Website bewusst ab, wenn Sie Inhalte von einer Originalseite kopiert haben. Letzteres kann sich insgesamt negativ für Ihrer google Platzierungen auswirken.
2. Was kann ich gegen Duplicate Content machen
Um Duplicate Content zu vermeiden sollten Sie unter allen Umständen einzigartige, neue Inhalte erstellen. Bei Produktseiten und Inhalten für verschiedene Länder mit der selben Sprache sollten Sie vor allem auf eine saubere technische Umsetzung setzen und mit cannonicals als hreflang arbeiten.
3. Warum ist Duplicate Content ein Problem?
Duplicate Content ist ein Problem, weil er Ihrer SEO massiv schadet. Google platziert Sie aufgrund von doppelten Inhalten schlechter oder indexiert ihre Seite im schlimmsten Fall gar nicht, wenn die Inhalte 1 zu 1 von einer anderen Seite kopiert wurden.
Unser Versprechen
Als Agentur wissen wir, dass viele Optimierungen im Tagesgeschäft untergehen. Wir haben uns auf Suchmaschinenoptimierung spezialisiert und helfen Ihnen gerne diese optimal auf Ihrer Website oder Ihrem Online-Shop umzusetzen. Die Vermeidung und Beseitigung von Duplicate Content gehört natürlich auch dazu. Sollte dieses Problem bei Ihnen gerade akut anstehen, melden Sie sich gerne bei uns zu einem kostenlosen Beratungsgespräch.
Brauchen Sie Unterstützung bei diesem Thema?
Sprechen Sie uns unverbindlich an und lassen Sie sich von uns beraten.
Crawl-Budget steuern, optimieren und bessere ranken
Eines der wichtigsten Themen für Websites, wenn es um Suchmaschinenoptimierung geht, ist nach wie vor Crawling und Indexierung. Vor allem: Dem Googlebot durch gezielte Steuerung des Crawlings alle Unterseiten und Produkte Ihrer Website zugänglich machen, sodass diese heruntergeladen und in…
So bauen Sie die perfekte Website-Struktur
Eine saubere Website-Struktur ist ein absolutes Muss für den User, ein wichtiger Aspekt für den Crawler und gleichzeitig eine Herausforderung für den komplexen Onlineshop. Besonders bei Shops mit breitem Warensortiment sollte bereits früh geplant werden, wie die Ebenenstruktur der Website…
Klickstarke Meta Tags in 4 Schritten
Sie wollen, dass Ihre Website potenzielle Käufer über die Suchmaschine anlockt? Dann sollten Sie sich darüber Gedanken machen, wie Ihre Website in den Suchergebnissen dasteht. Und zwar nicht nur für welche Suchbegriffe, sondern auch wie die Suchergebnisse aussehen: Regen Sie…


